Most explanations of PPO, GRPO, and RLHF open the same way: with a wall of formulas. Policy gradients, advantage functions, KL penalties, Monte Carlo estimators, old policies, reference models, clipping terms, reward models. All of it, all at once.
If you already think in reinforcement learning, that’s efficient. If your instincts were shaped by modern supervised training (cross entropy, next-token prediction, SFT, backprop), it’s a brick wall.
This article takes the other road. We start from the most familiar object in LLM training, supervised fine-tuning, and walk step by step until we arrive at policy gradient and GRPO. The whole journey is organized around one question:
If a model produces an output, and an external verifier scores that output, how do we update the model when the reward itself is not differentiable?
The answer isn’t magic. It’s one of the most useful tricks in all of reinforcement learning:
Don’t try to differentiate through the reward. Instead, raise the probability of outputs that beat a baseline, and lower the probability of outputs that fall short of it.
Once you see it that way, on-policy RL for LLMs stops being mysterious. The whole thing collapses into a single sentence:
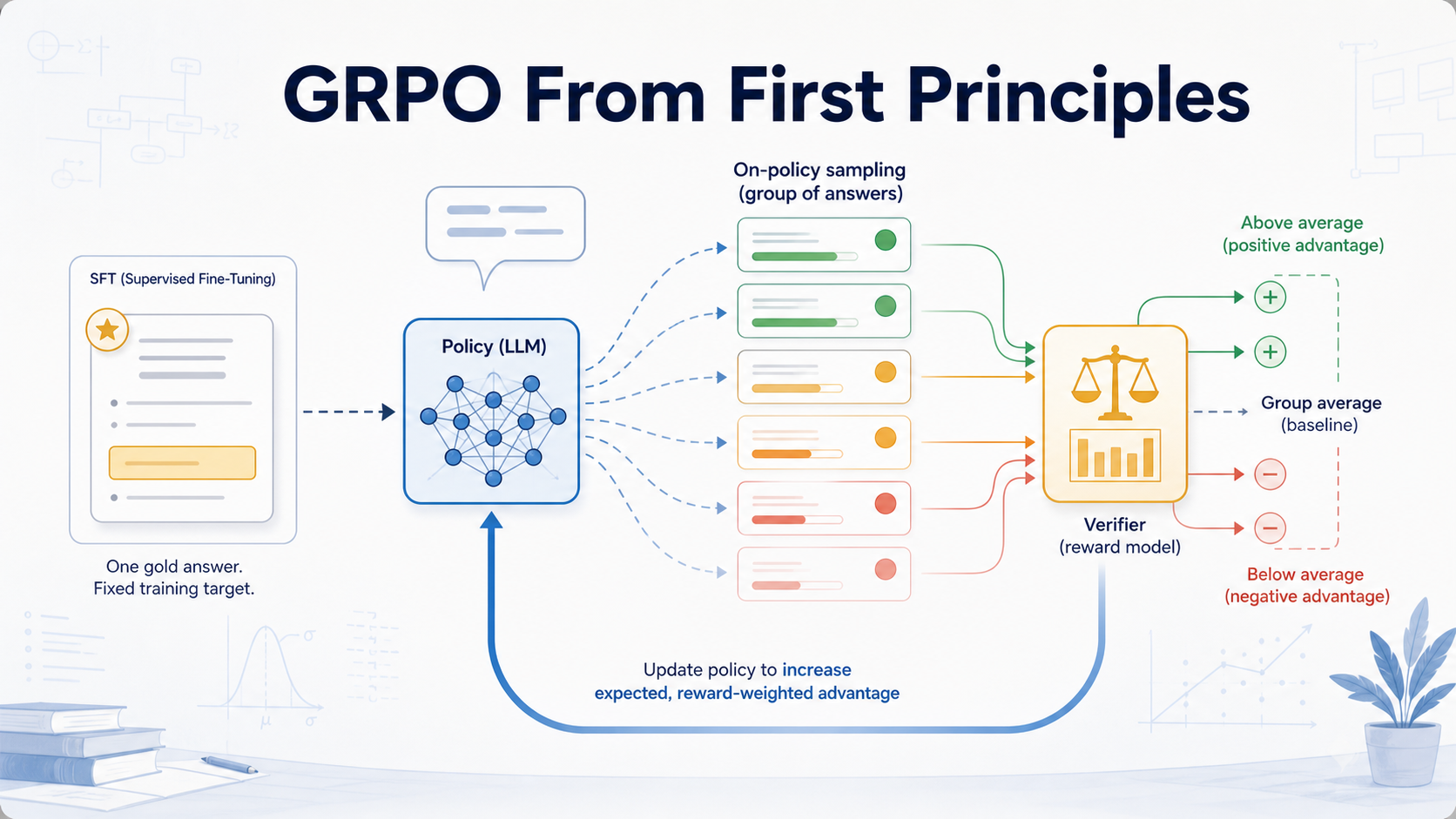
GRPO is dynamic, group-normalized, reward-weighted SFT on model-generated samples.
That sentence isn’t the entire story, but it’s the right thing to keep in your head as the story unfolds.
Table of Contents
- 1. The Teacher, the Student, and the Missing Answer Key
- 2. Generative AI Is Not Automatically Stochastic
- 3. The Deterministic Strategy and the Gradient Gap
- 4. The Stochastic Strategy: Optimize the Distribution
- 5. SFT First: Increasing the Probability of a Gold Answer
- 6. Why We Need the Log Trick
- 7. Monte Carlo: Engineering the Law of Large Numbers
- 8. From Gradient Estimator to Loss
- 9. GRPO: Group Relative Policy Optimization
- 10. Why KL Regularization Appears
- 11. When Should You Reach for SFT, DPO, PPO, or GRPO?
- 12. Beyond LLMs: Why Probability Matters
- 13. The Whole Picture
1. The Teacher, the Student, and the Missing Answer Key
Start in a classroom.
In supervised fine-tuning, the teacher hands the student both a question and the official answer. There’s nothing to explore. The student just learns an association:
“When I see this question, I should produce this answer.”
That’s SFT. It’s powerful, but at heart it’s imitation: the gold answer is treated as ground truth, full stop.
Reinforcement learning changes the deal. The teacher still poses a question, but now there’s no answer key. The student attempts something, and the teacher reacts: good, bad, partially right, too long, unsafe, elegant, wrong format. Feedback, not a solution.
This is much closer to how real problems actually work. The interesting ones rarely arrive with a gold response attached. You try, you get feedback, and over many rounds you develop a feel for which kinds of attempts tend to land.
So the philosophical split between the two is clean:
- SFT learns from a reference answer.
- RL learns from trial and error.
For LLMs, that trial-and-error loop is even possible because the model can sample different answers from its own distribution. But that innocent-sounding sentence hides something worth pausing on.
2. Generative AI Is Not Automatically Stochastic
You’ll often hear that generative AI is stochastic. That’s only half true.
An autoregressive LLM defines a probability distribution over the next token:
If we sample from that distribution, the model is stochastic: the same prompt can produce many different completions. But sampling is a choice, not a law. We could just as easily decode greedily:
Now the model is deterministic. Same prompt, same weights, same output, every time. In practice greedy decoding tends to be too rigid; it repeats itself and settles into bland high-probability ruts. Sampling is the trade: diversity and exploration on one side, uncertainty on the other.
This distinction matters more than it looks, because not every generative model is naturally policy-like. Some generators outside the LLM world (certain flow-matching models, for instance) behave like deterministic maps or velocity fields once you fix the noise, the solver, and the condition. They don’t hand you the convenient token-level log probabilities that an LLM gives away for free.
That’s why the next two sections work through two strategies side by side:
- a deterministic strategy, and
- a stochastic strategy.
If all we cared about were ordinary sampled LLMs, we could almost skip the deterministic case. But it’s worth the detour: the deterministic setup exposes the exact problem that policy gradient was invented to solve, and it sets up the non-LLM generators, like flow-matching TTS, where probability sometimes has to be deliberately added back in.
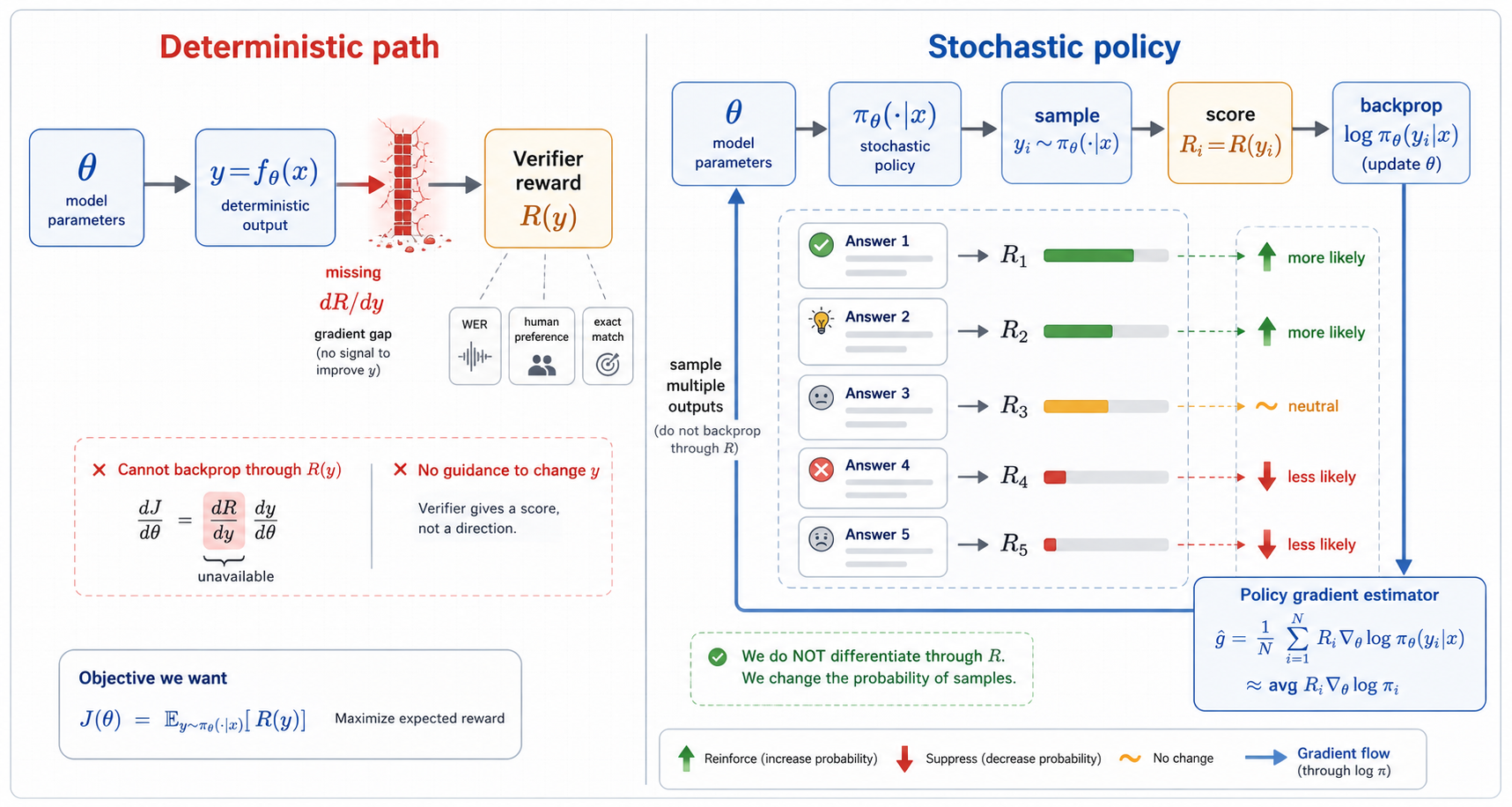
3. The Deterministic Strategy and the Gradient Gap
Suppose the model maps an input straight to an output, deterministically. (Picture a continuous generator here, not greedy LLM decoding. Greedy decoding is deterministic too, but for a different reason: the argmax is itself non-differentiable.)
An external reward function scores that output:
The most direct way to improve the model is to push that score up:
which calls for the gradient
and, by the chain rule,
The model side,
is no trouble at all. That’s just backprop. The trouble is the reward side:
Plenty of the rewards we actually care about simply don’t give us this gradient. A verifier reports whether an answer is correct. A human can prefer answer A to answer B. An ASR system emits a transcript, and WER comes out of an edit-distance computation. For a concrete sample, all of these can produce a label or score. What they do not produce is a useful gradient with respect to the model output.
So we hit a wall:
The reward tells us whether the output was good. It never tells us how to nudge the output to make it better.
Deterministic policy gradient methods have one answer to this: learn a critic, a Q-function that estimates long-term value.
If is differentiable in the action , a deterministic actor can ride its gradient uphill:
In effect, the critic supplies the missing direction: it tells us which way the action should move.
But for high-dimensional generation with sparse, black-box, verifier-style rewards, training a reliable critic is hard and often unstable. There’s a second route that sidesteps the whole problem. Instead of asking how the output should move, ask a different question entirely: which of the outputs I already sampled should become more likely?
That’s the stochastic strategy.
4. The Stochastic Strategy: Optimize the Distribution
A stochastic policy doesn’t commit to a single output. It defines a distribution:
Two notations that are easy to blur together:
- is the entire output distribution given .
- is the probability (or density) of one specific output .
The objective changes shape. We’re no longer maximizing the score of a single deterministic output. We’re maximizing expected reward over the distribution:
Written as an integral:
and for discrete outputs, the integral is just a sum:
This is nothing more exotic than a probability-weighted average reward. We want the model to move its probability mass toward the high-reward outputs.
And here’s the inversion that makes everything downstream work:
We don’t need to know how to edit a specific output to raise its reward.
We only need to know how to reshape the model so that high-reward sampled outputs become more likely.
5. SFT First: Increasing the Probability of a Gold Answer
Before deriving policy gradient, let’s re-anchor on SFT, because the two turn out to be siblings.
In SFT the dataset hands us a gold answer:
and the objective is maximum likelihood:
which is the same as minimizing cross entropy:
For an autoregressive LLM, the sequence probability factorizes token by token:
and taking the log turns that product into a sum:
So SFT, stripped to one line, says:
Given a trusted answer, raise the log probability of the token path that produces it.
Hold onto that shape. Policy gradient is going to look almost identical, with one decisive change: the answer is sampled by the model itself, and its weight comes from reward.
6. Why We Need the Log Trick
We want the gradient of the objective:
Start from the integral form:
and differentiate:
This is correct, but it’s stuck. We can’t estimate it by sampling from yet, and sampling is the only thing we can actually do. Monte Carlo estimation needs the integrand to wear a particular costume:
because then we can draw samples
and approximate the expectation by averaging:
The snag is that our gradient contains
not the bare
that the Monte Carlo form requires out front. We need to coax back into that leading position.
Enter the score-function trick. It starts from the ordinary derivative of a log:
Rearranged, that’s exactly the substitution we need:
Drop it back into the gradient:
and now the integrand is in Monte Carlo costume,
so the gradient is just an expectation:
This is the REINFORCE estimator, also called the score-function or likelihood-ratio estimator.
One thing to keep straight through all of this: the reward is a constant with respect to . It’s a black box that hands back a number, nothing more. Differentiable pieces like a KL penalty don’t live inside ; they’re tacked on separately as their own loss term.
And notice why the log showed up. It wasn’t a clever nod to SFT. It appeared because we had to rewrite
so that the gradient could be estimated by sampling from . The resemblance to SFT is a consequence, not the motivation, which is exactly what makes it satisfying.
7. Monte Carlo: Engineering the Law of Large Numbers
The exact expectation is hopeless to compute, because the output space is astronomically large. This is the practical pain that the clean notation quietly papers over.
In the integral, ranges over every possible output:
Mathematically that’s well-defined. Computationally it’s a fantasy. We can’t loop over every completion an LLM might produce, score each one, take each log-prob gradient, and sum it all up.
So we don’t. We sample:
and estimate:
That’s Monte Carlo estimation, and the engine underneath it is the law of large numbers:
This is the moment the symbols turn into computation. The abstract variable becomes a handful of concrete samples , and every term in the sum is something we can actually evaluate:
| Symbol | Meaning | Can we compute it directly? |
|---|---|---|
| A variable over the entire output space | No: too many possible outputs to enumerate. | |
| One sampled output from the current model | Yes: it’s a concrete sequence. | |
| Reward of that sampled output | Yes: the verifier returns a scalar. | |
| Gradient of the sample’s log probability | Yes: ordinary backprop, exactly like SFT. |
The name “Monte Carlo” is just a label for this practice: the samples are model outputs, the function is reward times score, and their average estimates the gradient. This is where trial and error becomes mathematics, and it lines up perfectly with the classroom. The student tries several answers, the teacher scores them, and the update rule reads:
Answers that scored higher should become more likely next time.
8. From Gradient Estimator to Loss
In practice we don’t hand-code gradients. We write a loss and let backprop do the rest.
For a single sampled output , the simplest policy-gradient loss is:
In real systems, though, we almost always swap the raw reward for an advantage:
The advantage answers a sharper question: was this output better than some baseline?
Why are we allowed to subtract a baseline at all? Because as long as doesn’t depend on the sampled action, it vanishes in expectation:
So the baseline leaves the expected gradient untouched; it only cuts the variance. This is the first place engineering quietly enters the story: the estimator is unbiased but noisy, so we reshape the reward into a steadier learning signal without biasing it.
The sign of the advantage is what drives learning. When
minimizing the loss pushes the log probability of up. When
it pushes that log probability down. Good attempts get reinforced; bad ones get suppressed.
And this is precisely why policy gradient feels like a weighted version of SFT. Put them next to each other:
The difference is not cosmetic. In SFT the answer comes from the dataset and is trusted as gold. In policy gradient the answer is sampled by the current model and weighted by feedback. Same skeleton, completely different source of truth.
The same contrast, with GRPO added as the natural next step:
| Method | Where the answer comes from | What is optimized | Mental model |
|---|---|---|---|
| SFT | A gold answer from the dataset | Imitate the answer key. | |
| Policy gradient | A sample from the current model | Reinforce the better attempts. | |
| GRPO | A group of samples from the current model | , with group-relative | Reward-weighted SFT, weights normalized within the group. |
For an autoregressive LLM, one detail is worth spelling out: the sequence-level advantage multiplies the entire sum of token log-probabilities:
Every token in the sampled answer inherits the same sequence-level feedback. As credit assignment goes, that’s blunt, but the bluntness is exactly what keeps the method simple enough to scale.
So the classroom metaphor sharpens into something precise:
- SFT is memorizing the teacher’s answer key.
- Policy gradient is trying several answers, collecting scores, and reinforcing the strategies that worked.
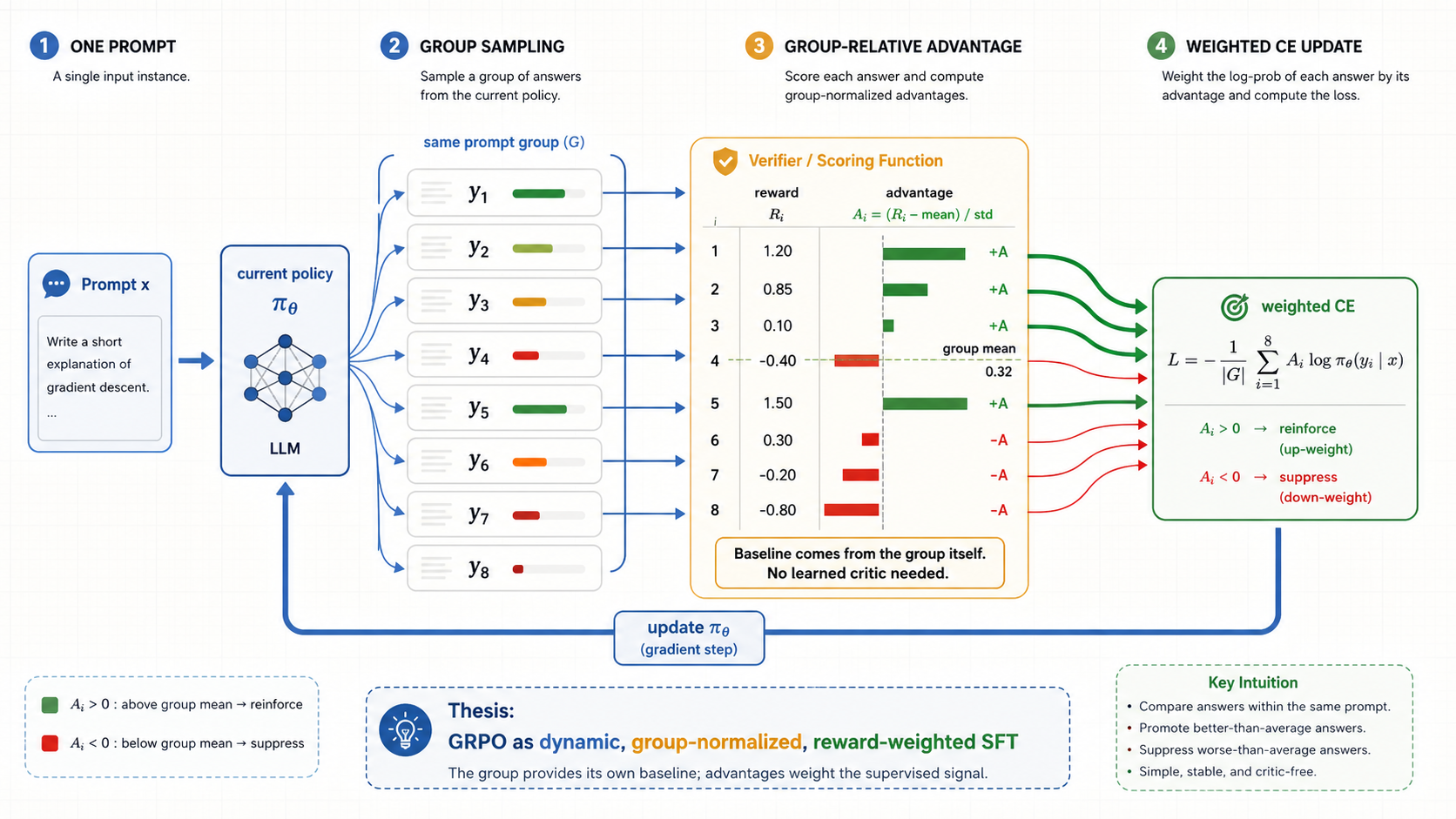
9. GRPO: Group Relative Policy Optimization
GRPO stands for Group Relative Policy Optimization, and the core idea is almost embarrassingly simple.
For a single prompt , sample a whole group of outputs at once:
score each one:
and then build a group-relative advantage by standardizing those scores against each other:
This converts raw rewards into something closer to class rank. A sample doesn’t have to be perfect, or even objectively good. It just has to land above the group average to get reinforced. That’s the whole trick: no separately trained critic, no learned value baseline. The other samples in the group are the baseline.
From there it’s the same weighted-logprob loss we already have:
Production GRPO bolts on a few stabilizers (old-policy probability ratios, clipping, KL regularization against a reference model, reward normalization), but none of them disturb the mental model:
Sample several answers. Score them. Standardize the scores within the group. Push up the probability of the above-average samples and push down the below-average ones.
Which is why GRPO is fairly read as dynamic weighted SFT: the weights aren’t fixed in a dataset, they’re constructed online from group-relative reward.
10. Why KL Regularization Appears
Reward functions are imperfect, and a model under optimization pressure is very good at finding the cracks.
Optimize the reward and nothing else, and the model will happily exploit the verifier rather than the task. A text model discovers strange formatting tricks. An audio model learns to be easy for an ASR verifier to transcribe while sounding unnatural to a human ear. A code model overfits the unit tests and ships brittle solutions. Reward hacking, in every flavor.
The standard guardrail is to keep the model tethered to a reference model
with a KL penalty:
The two forces balance against each other. Reward pulls the model toward outputs that score better; KL holds it near a distribution we already trust. It isn’t mathematical decoration; it’s the practical brake that keeps reward optimization from driving off a cliff.
11. When Should You Reach for SFT, DPO, PPO, or GRPO?
None of this is an argument that GRPO is the best tool. The point is narrower and more useful: GRPO solves a particular kind of problem, and knowing which problem you have tells you which tool to grab.
If you have gold answers, SFT is the simplest thing that works:
If you have a fixed set of preference pairs, methods like DPO are the natural fit. However those pairs were collected, the update treats them as an offline dataset: no fresh on-policy sampling each step, just a differentiable objective over the policy and a reference.
If you have an external reward or verifier that can score the current model’s outputs but can’t hand back a useful gradient, policy-gradient methods like PPO and GRPO come into their own.
If your reward and your generation path are both fully differentiable and the gradient is trustworthy, skip the estimator entirely and backpropagate directly; it usually has lower variance than a score-function estimate. If a reward can be written as a smooth differentiable loss, there’s no reason to launder it through REINFORCE.
As a quick decision table:
| What you have | Typical method | Why |
|---|---|---|
| Gold answers | SFT | The answer key is known: just maximize its likelihood. |
| Fixed / pre-collected preference pairs | DPO-style preference optimization | The comparison data already exists offline. |
| Online black-box rewards | PPO / GRPO-style policy gradient | The verifier scores samples but offers no usable gradient. |
| Differentiable rewards and differentiable generation | Direct reward loss | If the gradient is trustworthy, use it instead of estimating it. |
The headline: GRPO isn’t valuable because rewards are computable. It’s valuable because so many of the rewards we actually want are not reliably differentiable.
12. Beyond LLMs: Why Probability Matters
For a standard sampled LLM, the policy distribution is handed to you for free. The model emits token probabilities, you sample from them, and you can read off
for whatever sequence you sampled. Everything above just works.
For other generative models, that’s not guaranteed.
Take a flow-matching generator. It may begin from sampled base noise and then follow a deterministic trajectory through a learned velocity field. The subtle catch is that, unlike an LLM, it may never expose a trainable log probability, neither for the intermediate steps nor for the final trajectory.
And the moment that term goes missing, the policy-gradient story falls apart:
needs a probability model with tractable log probabilities. Strip out and the score-function update has nothing left to backpropagate through.
This is why some non-LLM systems that want GRPO-style training have to make their generation probabilistic first, or otherwise manufacture the log probabilities that policy gradient depends on. In flow-matching TTS, for example, the model can be set up to sample from an output distribution instead of emitting a single deterministic velocity. Once the trajectories carry log probabilities, policy-gradient training is back on the table.
That’s the bridge to systems like F5-R-style TTS: if you want to optimize black-box rewards such as WER or speaker similarity with policy gradient, the generator has to supply not just samples but the log probabilities of those samples. No log-probs, no policy gradient.
13. The Whole Picture
Here’s the entire chain in one place.
We want to maximize expected reward:
Write it as an integral:
Take the gradient:
Apply the score-function trick:
which turns the gradient into an expectation:
estimate it with Monte Carlo:
implement it as weighted log-prob training:
and, for GRPO, build the weights by comparing samples within a group:
Which leaves the mental model right where we started, now fully earned:
SFT raises the probability of gold answers.
Policy gradient raises or lowers the probability of sampled answers according to advantage.
GRPO constructs those weights by comparing samples within the same group.
That’s the missing bridge between classical reinforcement learning and modern LLM post-training, and it’s why GRPO, for all its production machinery, is best understood as dynamic, group-normalized, reward-weighted SFT on the model’s own samples.